Learning Self-Supervised Low-Rank Network for Single-Stage Weakly and Semi-Supervised Semantic Segmentation
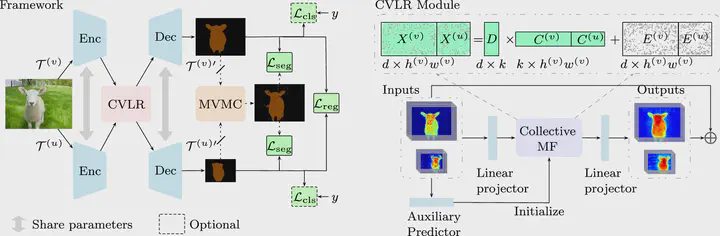
Semantic segmentation with limited annotations, such as weakly supervised semantic segmentation (WSSS) and semi-supervised semantic segmentation (SSSS), is a challenging task that has attracted much attention recently. Most leading WSSS methods employ a sophisticated multi-stage training strategy to estimate pseudo-labels as precise as possible, but they suffer from high model complexity. In contrast, there exists another research line that trains a single network with image-level labels in one training cycle. However, such a single-stage strategy often performs poorly because of the compounding effect caused by inaccurate pseudo-label estimation. To address this issue, this paper presents a Self-supervised Low-Rank Network (SLRNet) for single-stage WSSS and SSSS. The SLRNet uses cross-view self-supervision, that is, it simultaneously predicts several complementary attentive LR representations from different views of an image to learn precise pseudo-labels. Specifically, we reformulate the LR representation learning as a collective matrix factorization problem and optimize it jointly with the network learning in an end-to-end manner. The resulting LR representation deprecates noisy information while capturing stable semantics across different views, making it robust to the input variations, thereby reducing overfitting to self-supervision errors. The SLRNet can provide a unified single-stage framework for various label-efficient semantic segmentation settings: (1) WSSS with image-level labeled data, (2) SSSS with a few pixel-level labeled data, and (3) SSSS with a few pixel-level labeled data and many image-level labeled data. Extensive experiments on the Pascal VOC 2012, COCO, and L2ID datasets demonstrate that our SLRNet outperforms both state-of-the-art WSSS and SSSS methods with a variety of different settings, proving its good generalizability and efficacy.
Dingwen Zhang
Professor of Northwestern Polytechnical University
Dingwen Zhang (张鼎文)is a Professor at BRAIN Lab, NWPU. He obtained his B.S. and Ph.D. degrees from School of Automation, Northwestern Polytechnical University (NWPU) in 2012 and 2018, respectively.