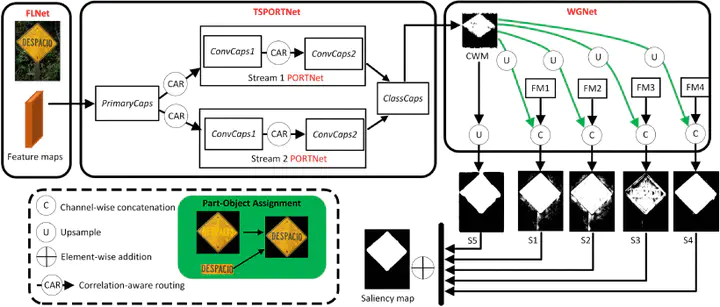
Recent years have witnessed a big leap in automatic visual saliency detection attributed to advances in deep learning, especially Convolutional Neural Networks (CNNs). However, inferring the saliency of each image part separately, as was adopted by most CNNs methods, inevitably leads to an incomplete segmentation of the salient object. In this paper, we describe how to use the property of part-object relations endowed by the Capsule Network (CapsNet) to solve the problems that fundamentally hinge on relational inference for visual saliency detection. Concretely, we put in place a two-stream strategy, termed Two-Stream Part-Object RelaTional Network (TSPORTNet), to implement CapsNet, aiming to reduce both the network complexity and the possible redundancy during capsule routing. Additionally, taking into account the correlations of capsule types from the preceding training images, a correlation-aware capsule routing algorithm is developed for more accurate capsule assignments at the training stage, which also speeds up the training dramatically. By exploring part-object relationships, TSPORTNet produces a capsule wholeness map, which in turn aids multi-level features in generating the final saliency map. Experimental results on five widely-used benchmarks show that our framework consistently achieves state-of-the-art performance. The code can be found on https://github.com/liuyi1989/TSPORTNet .
Dingwen Zhang
Professor of Northwestern Polytechnical University
Dingwen Zhang (张鼎文)is a Professor at BRAIN Lab, NWPU. He obtained his B.S. and Ph.D. degrees from School of Automation, Northwestern Polytechnical University (NWPU) in 2012 and 2018, respectively.