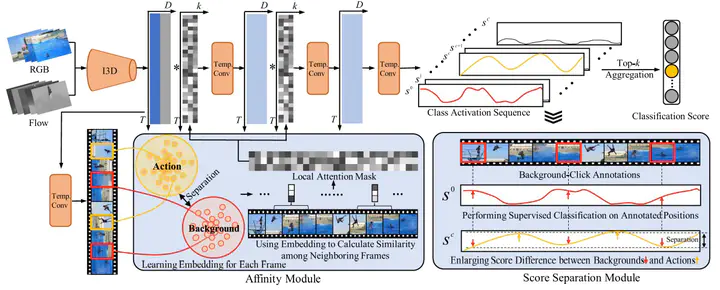
Weakly supervised temporal action localization aims at learning the instance-level action pattern from the video-level labels, where a significant challenge is action-context confusion. To overcome this challenge, one recent work builds an action-click supervision framework. It requires similar annotation costs but can steadily improve the localization performance when compared to the conventional weakly supervised methods. In this paper, by revealing that the performance bottleneck of the existing approaches mainly comes from the background errors, we find that a stronger action localizer can be trained with labels on the background video frames rather than those on the action frames. To this end, we convert the action-click supervision to the background-click supervision and develop a novel method, called BackTAL. Specifically, BackTAL implements two-fold modeling on the background video frames, i.e., the position modeling and the feature modeling. In position modeling, we not only conduct supervised learning on the annotated video frames but also design a score separation module to enlarge the score differences between the potential action frames and backgrounds. In feature modeling, we propose an affinity module to measure frame-specific similarities among neighboring frames and dynamically attend to informative neighbors when calculating temporal convolution. Extensive experiments on three benchmarks are conducted, which demonstrate the high performance of the established BackTAL and the rationality of the proposed background-click supervision.