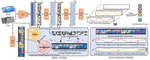
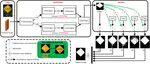
Recent years have witnessed a big leap in automatic visual saliency detection attributed to advances in deep learning, especially Convolutional Neural Networks (CNNs). However, inferring the saliency of each image part separately, as was adopted by most CNNs methods, inevitably leads to an incomplete segmentation of the salient object.